



- 2008.08.12 마소 컬럼 Lucene 2부
- 2008.08.12 마소 컬럼 Lucene 1부
- 2008.08.03 가족이 필요해 3부 예고
- 2008.08.03 가족이 필요해 2부
- 2008.07.27 Shell 프로그래밍
- 2008.07.27 가족이 필요해 1회 - 가족 모이다
- 2008.07.20 가족 버라이어티 탄생 - MBC Every one 가족이 필요해
- 2008.07.20 다음 tv팟 게임동영상 전용 게임섹션 오픈~
- 2008.07.05 IT 취업 어떻게 했나....(개발자) 3
- 2008.07.05 약 2달 반만에 블로깅을 다시 시작하다....?
( 월간 마이크로 소프트웨어 9월 연재 )
서문
지난 호에서는 lucene의 소개와 함께 기본적인 내용에 대해서 다루어 보았다. 이번 호에서는 Apache Lucene 의 코어 클래스 위주로 깊이 있게 다루고자 한다.
Lucene의 핵심 요소인 Analyzer와 인덱스 튜닝 그리고 고급 검색기법 등에 대해 다루어 보고자 한다. 또한 이슈가 되고 있는 여러 문제점과 해결방안에 대해서도 같이 알아보자.
1. Analyzer
지난 회에선 Apache Lucene이 기본적으로 제공하는 4가지 built-in Analyzer에 대해 살펴 보았다. 이번 회 에서는 Analyzer에 대해 좀 더 상세히 살펴보고 Analyzer를 커스터마이징 하고 직접 작성해 보자. Lucene API의 org.apache.lucene.analysis 패키지를 보면 4개의 built-in Analyzer ( StopAnalyzer, SimpleAnalyzer, WhitespaceAnalyzer, StandardAnalyzer ) 와 함께 Token, Tokenizer, TokenStream, TokenFilter 등이 있다.
이중 주의 깊게 살펴 보아야 할게 Tokenizer 와 TokenFilter 인데 이 두 클래스가 Analyzer를 구성하는 핵심 요소가 된다. Tokenizer 와 TokenFilter는 모두 TokenStream을 상속받은 자식 클래스 로서 input 값을 입력 받아 Token 단위로 다양한 처리를 한다. 이 두 클래스의 차이점으로는 Tokenizer는 개별 문자(characters) 단위로 데이터를 처리하고 TokenFilter는 단어(words) 단위로 처리를 하며 Tokenizer는 Reader 타입의 입력 값을 받아서 처리하는 반면 TokenFilter는 아래 <그림1>의 클래스 계층 구조도 에서 짐작 할 수 있듯이 부모 객체인 TokenStream 형태로 입력 값을 받아서 사용한다. <그림1>은 lucene 에서 사용되는 TokenStream의 클래스 계층 구조도 인데 클래스 명만 봐도 어떤 역할을 하는지 대략 상상 할 수 있을 것 이다. 각각의 자세한 사용법이나 설명은 API를 참고 하도록 하고 이제 이러한 TokenStream을 조합해서 간단한 Analyzer를 작성해 보도록 하자.
실행 가능한 전체 소스는 '이달에 디스크'를 통해 확인할 수 있으며, <리스트1>에서는 핵심 코드만 추출하였다. TestAnalyzer 라는 새로운 Analyzer를 정의 하기 위해서 부모 클래스인 Analyzer를 상속 받고 tokenStream() 메소드를 재정의 해주면 된다.
이때 앞서 설명한 TokenFilter의 강력한 메커니즘을 엿볼 수 있는데 <리스트1>에서 tokenStream() 메소드 부분을 보면 다양한 Filter들을 TokenStream result = new LowerCaseFilter(result) 와 같은 방법으로 손쉽게 적용 하였다. 이는 TokenFilter가 TokenStream을 상속받으면서 입력값으로 TokenStream을 받아서 사용하기에 가능한 일이다. 전체 소스에서는 StandardToekenizer, StandardFilter, LowerCaseFilter, StopFilter 등을 사용하였다.

<리스트1> TestAnalyzer.java
public class TestAnalyzer extends Analyzer {
…..
public TokenStream tokenStream(String fieldName, Reader reader){
TokenStream result = new StandardTokenizer(reader);
result = new StandardFilter(result);
result = new LowerCaseFilter(result);
return result;
}
…..
}
2. 문서의 파싱
지난 호에 소개한 간단한 인덱싱 예제(이달의 디스크 SimpleIndex.java) 에서는 단순히 입력받은 문자열을 분석하여 색인화 하는 과정을 거쳤다. 하지만 실전에서는 이와 같은 단순한 문자열 입력 보다는 다양한 문서를 색인화 하는 검색 하는 작업이 더 빈번할 것이다. XML , PDF, HTML, MS WORD 와 같이 다양한 문서들을 색인화 하기 위해서는 <그림2> 에서와 같이 각각의 문서를 Lucene의 Analyzer가 이해할 수 있도록 해석(parse)해서 텍스트로 추출해 내는 과정이 필요하다. Lucene 패키지 안에도 편의를 제공하기 위한 클래스가 몇몇 존재하기는 하지만 아무래도 외부 서드파티 라이브러리에 의존적일 수 밖에 없다. 이번 연재는 색인화 과정의 이해와 튜닝에 주 초점을 두고 있으니 다양한 라이브러리에 대한 상세한 설명은 생략하기로 한다. 단 아래 <표1>에 이들 라이브러리에 대한 목록과 참고 사이트를 분류해 놓았으니 참고 하도록 하자.

<그림2> 문서의 색인화 과정
|
XML |
Dom, Sax, JDom, Piccolo (http://piccolo.sourceforge.net) Apache Disester (http://jakarta.apache.org/commons/digester/) |
|
PDF |
PDFBox (http://www.pdfbox.org), IndexFiles (lucene built-in) , LucenePDFDocument (lucene built-in) Xpdf (http://www.foolabs.com/xpdf) JPedal (http://www.jpedal.org) Etymon PJ( http://www.etymon.com) |
|
Html |
Jtidy (http://jtidy.sourceforge.net ), HTMLParser( http://htmlparser.sourceforge.net) |
|
MS Word |
POI (http://jakarta.apache.org/poi ) Text Extractors( http://textmining.org ) Antiword ( http://www.winfield.demon.nl) OpenOffice SDK ( http://www.openoffice.org ) |
<표 1> 문서 파싱을 위한 라이브러리
3. 인덱스 오퍼레이션
지난 연재에서는 간단한 색인화 과정을 거처 인덱스 파일을 생성 시켜 보았었고 이번 단원에서는 이미 생성된 인덱스 파일에서 내용을 추가,수정,삭제 하는 법에 대해 알아보도록 하자. Lucene 에서 인덱스 파일은 바이너리 형태로 존재해 개발 언어나 플랫폼에 구애 받지 않으므로 여러 가지로 상당히 편리하다. 가령 자바 언어로 작성된 서버 프로그램과 윈도우 기반의 클라이언트 프로그램 과의 인덱스 파일을 공유하거나 동기화 작업등을 처리 할 때 상당한 이점이 있을 것이다. <리스트2> AppendIndex.java 예제는 인덱스 파일에 색인을 추가하는 예제 이다. 지난호에 소개한 SimpleIndex.java와의 차이점 이라면 단지 (1) 번 라인에서와 같이 IndexWriter 객체 생성시 생성자의 세번째 인자값에 true 대신 false를 사용한다는 것 뿐이다. True 일때는 인덱스 파일을 새로 생성하거나 덮어 쓰지만 false이면 기존 인덱스 파일에 Document를 추가하게 된다. 그리고 인덱스 파일을 읽거나 수정 또는 삭제 시 편의를 위해 (2)번 라인과 같이 keyword 필드를 추가하였다. 그럼 이제 생성된 인덱스 파일을 이용해 수정과 삭제 처리를 해보자. 수정과 삭제 처리를 위해서는 Lucene 패키지에 포함된 IndexReader(org.apache.lucene.index.IndexReader) 클래스를 사용하는데 delete() 메쏘드 외에도 여러가지 편리하고 직관적인 메쏘드들을 많이 제공하므로 API를 한번쯤 찾아 보는 것도 좋을 것이다. <리스트3>은 삭제 예제인데 (1)번 라인 에서와 같이 검색 Term 객체를 인자로 받아서 삭제하거나 (2)번 라인과 같이 keyword 필드의 id값을 이용해 삭제하는 것도 가능하다. 다만 한가지 기억하고 넘어갈 사항이 있는데 IndexReader 의 delete() 메소드는 Document를 즉시 삭제 하지 않고 '삭제' 상태로 마크 처리했다가 IndexReader 객체의 close() 후 IndexWireter 객체에 의해 인덱스 파일이 merge 된 후에야 완전히 삭제 처리 되므로 이미 수행한 명령을 롤백(undelete() 메쏘드)하거나 최종확정(commit() 메쏘드) 하는 것도 가능하다. '이달의디스크' 에서 전체 소스를 받아 실행 시켜 보면 시스템 로깅을 통해 확인 가능할 것이다. 그리고 인덱스의 업데이트 과정은 이미 소개한 삭제와 추가 예제의 조합이므로 굳이 추가적인 설명을 하지는 않겠다.
<리스트2> AppendIndex.java
…..
private void index() throws IOException {
Directory dir = FSDirectory.getDirectory("디렉토리경로", true);
Analyzer analyzer=new WhitespaceAnalyzer();
IndexWriter writer = new IndexWriter(dir, analyzer, false); ---------(1)
for (int i = 10; i < 20; i++) {
Document doc = new Document();
doc.add(Field.Keyword("id",i+"")); ------------------(2)
doc.add(Field.Text("title", "title is …"));
doc.add(Field.Text("content", "content is…."));
writer.addDocument(doc);
}
writer.optimize();
writer.close();.
}
…..
<리스트3> DeleteIndex.java
…
private void deleteIndex() throws IOException {
String dirPath="인덱스 파일 경로";
IndexReader reader=IndexReader.open(dirPath);
reader.delete(new Term("title","apache")); --------------(1)
reader.delete(1); -----------------------(2)
reader.close();
}
…..
4. 인덱스 튜닝
소위 검색 엔진이라 불리는 편리한 도구의 뒷면 에는 색인화 라는 무시무시한 괴물이 존재하고 있다. 필자의 경우엔 약 8천만건 정도 되는 DB데이터를 Lucene을 이용해 색인화 작업을 한적이 있는데 엄청난 Disk용량은 물론 이거니와 색인화 작업이 완료될 때 까지 걸리는 그 지루하고도 무지막지한 시간을 생각하면 아직도 치가 떨릴 지경이다. 이번 단원 에서는 대용량의 색인화 작업을 위해 알아둬야 할 몇 가지 사항에 대해 소개하고자 한다. 우선 Lucene을 이용한 색인화 작업에서 병목현상이 가장 빈번하게 발생하는 부분은 바로 Disk에 인덱스 파일을 쓰는 작업 일 것 이다. 몇 건 안되는 문서의 색인화 작업시 에는 디폴트 설정을 그대로 사용해서 색인화 해도 별 무리가 없지만 대량의 색인화 작업시 이러한 병목 현상을 줄이기 위해 IndexWriter 클래스는 <표2>와 같이 몇 가지 멤버 변수 설정을 제공한다. 인덱스 튜닝을 위한 첫번째 요소로 mergeFactor 가 있다. mergeFactor는 Disk에 쓰기전 얼마나 많은 문서를 메모리에 저장할 것인가에 대한 요소이며 또한 인덱스 Segment 를 얼마나 자주 병합(merge) 시킬 것인가를 결정 짓는다. 디폴트 값이 10 이므로 별다른 설정을 하지 않으면 1개의 segment를 쓰기 전에 10개의 Document를 메모리에 저장 하게 되며, 10개의 segment를 10배 용량을 가지는 하나의 segment 로 병합 가능하게 한다. 그리고 두번째 요소인 maxMergeDocs 는 한 segment 내에 담을 수 있는 Document 개수를 제한한다. 만약 mergeFactor의 값을 10000으로 하고 maxMergeDocs의 값을 1000으로 한다면 1000개의 Document를 포함 하는 segment 10개가 인덱싱 작업의 결과로 남게 된다. 이처럼 maxMergeDocs 를 크게 설정하면 인덱싱 시간은 줄어 들지만 대신 segment 파일의 개수가 많아 지므로 검색 작업시 불필요한 처리 시간을 소모하게 된다. 따라서 mergeFactor를 크게 잡은 경우엔 IndexWriter의 optimize() 메쏘드를 사용해 여러 segment를 병합시켜 주는 것이 좋다. 마지막으로 minMergeDocs 는 segment에 담길 Document에 대해 버퍼 처리를 얼마나 할지를 결정한다. 기본값이 10이므로 10개의 Document 를 버퍼링 해서 segment에 쓰게 된다. 얼핏 보면 mergeRactor와 비슷한 것 같지만 minMergeDocs 는 RAM 메모리를 사용해 버퍼링할 개수 만을 지정하며 Segment의 사이즈나 처리 개수에 대해서는 관여하지 않는다.
<리스트4> 는 mergeFactor, maxMergeDocs, minMergeDocs를 적용한 IndexTuning 샘플 예제이며 <리스트5>는 출력된 실행결과 이다. 개인 컴퓨터의 사양에 따라 결과가 조금씩 다르겠지만 각 요소의 적용시 minMergeDocs 를 크게 잡아줄 때가 가장 속도가 빠른 것을 확인할수 있을것이다.
java maso.lucene.indexing.IndexTuning mergeFactor maxMergeDocs minMergeDocs 와 같이 실행 가능하며, 예외 처리가 되지 않은 간단한 테스트 용이므로 해당 파라메터를 넘겨주지 않고 실행하면 에러가 발생한다.
|
변수명 |
속성 명 |
디폴트 값 |
설명 |
|
mergeFactor |
Ogr.apache.lucene.mergeFactor |
10 |
Segment가 merge되는 빈도수와 사이즈를 컨트롤 한다. |
|
maxMergeDocs |
Org.apache.lucene.maxMergeDocs |
Integer.MAX_VALUE |
하나의 segment에 담길 Document 의 개수를 제한한다. |
|
minMergeDocs |
Org.apache.lucene.minMergeDocs |
10 |
색인 처리시 버퍼링에 사용될 RAM의 사이즈를 컨트롤 한다. |
<표2> 인덱스 퍼포먼스 튜닝을 위한 요소들
<리스트4> IndexTuning.java
public class IndexTuning {
private void index(int mergeFactor_i, int maxMergeDocs_i, int minMergeDocs_i) throws IOException {
……
Analyzer analyzer=new WhitespaceAnalyzer();
IndexWriter writer = new IndexWriter(dir, analyzer,true);
writer.mergeFactor=mergeFactor_i;
writer.maxMergeDocs=maxMergeDocs_i;
writer.minMergeDocs=minMergeDocs_i;
……
System.out.println("소요 시간: "+(endTime-startTime)+" ms");
}
public static void main(String[] args) throws IOException {
IndexTuning indexTunning = new IndexTuning();
indexTunning.index(Integer.parseInt(args[0]),Integer.parseInt(args[1]),Integer.parseInt(args[2]));
}
}
<리스트5> IndexTuning.java 실행 결과
mergeFactor = 10
maxMergeDocs = 9999
minMergeDocs = 10
소요 시간: 54407 ms
mergeFactor = 100
maxMergeDocs = 9999
minMergeDocs = 10
소요 시간: 44312 ms
mergeFactor = 10
maxMergeDocs = 9999
minMergeDocs = 100
소요 시간: 9938 ms
mergeFactor = 100
maxMergeDocs = 9999
minMergeDocs = 100
소요 시간: 8453 ms
5. 이슈 및 문제 해결
system lock
Lucene은 기본적으로 read시엔 락이 없지만 create,update,delete 시엔 항상 시스템 락을 건다 ( /temp/lucene-xxxxx.lock ) 일련의 작업이 끝난후 IndexWriter가 close 될때 락을 해제하게 되는데 제대로 close 되지 않았거나 중간에 에러가 발생할 경우엔 Rock 이 해제되지 않은 채로 존재하기 때문에 옵티마이징이나 기타 다른 작업을 할수가 없다. 따라서 이때는 해당 락을 직접 삭제해줘야 한다.
(예외 : java.io.IOException: lock obtain timed out ... C:\temp\lucene-xxxxxxxxxxxx.lock )
최대 파일 열기 개수 초과 오류 ( Too many open files Exception )
Lucene을 이용해 검색 작업을 하다 보면 종종 '최대 파일 열기 개수 초과' 라는 예외상황이 발생하곤 한다. 이때 가장 먼저 체크 해봐야 할 곳은 인덱스 파일이 생성된 디렉토리 이다. 인덱스 파일이 수많은 segment 로 구성되어 있다면 IndexWriter 의 optimize() 를 이용해서 하나의 segment로 수정해줘야 한다. 인덱스 옵티마이징 이후에도 똑 같은 에러가 계속해서 발생 된다면 인덱스 파일을 읽어 들이는 IndexReader 객체가 사용 후 제대로 반환 되는지 체크해 볼 필요가 있다. Lucene의 IndexReader 는 쓰레드에 안전 하므로 풀링 기법 을 사용하거나 싱글톤 패턴을 적용시켜 사용하는 것이 좋다.
이런 저런 문제도 아닌 경우엔 OS에서 허용 가능한 파일 오픈 개수를 늘려줘야 한다.
비 영어권 문자의 검색
한글,중국어,일어 와 같은 아시아권 문자의 검색을 위해서는 utf-8 인코딩을 사용하면 비교적 간단 하게 해결 되지만 형태소 검색과 같은 기능은 구현하기 힘들게 된다. 이때는 lucene 의 sandBox에 포함된 CJK Analyzer를 사용하면 되는데 아래 링크에서 다운로드 받을 수 있다.
http://svn.apache.org/repos/asf/lucene/java/trunk/contrib/analyzers/src/java/org/apache/lucene/analysis/cjk/
CJKAnalyzer 적용에 관한 보다 상세한 자료는 윤용현님의 사이트인 jazzzvm.com 을 참고하자. ( http://www.jazzvm.net/board/view.jazz?code=864593&seq=827¤tPage=1¤tBlock=1 )
덧 붙여 CJKAnalyzer는 내부적으로 StopFilter를 사용하므로 다운로드 받은 CJKAnalyzer 의 멤버변수인 String[] STOP_WORDS 에 기본적인 불용어(StopWord)를 추가 해서 사용하는 것도 괜찮을 것이다.
6. Query Syntax (http://lucene.apache.org/java/docs/queryparsersyntax.html)
기본쿼리
tiele 필드와 text 필드에서 AND 검색을 하려면 아래 (1)과 같이 [필드명:검색어 AND 필드명:검색어] 와 같은 질의를 사용 가능하다. 디폴트 필드가 text 일 경우 (2)번 질의와 같이 text 필드를 생략 할 수 있다.
title:"The Right Way" AND text:go -----------(1)
title:"Do it right" AND right ------------(2)
와일드카드 검색
? : 단일 문자 와일드카드
* : 다수 문자 와일드카드
와일드 카드에 사용되는 기호는 검색어의 중간이나 끝에 위치 가능하며 검색어의 시작 단어로는 사용할 수 없다.
Fuzzy 검색
roam~ 과 같은 검색 키워드를 사용하면 foam, roams와 같은 유사 검색을 한다.
Proximity 검색
한 문서 안에서 각각 10 단어 내에서 "apache"와 "jakarta"를 검색하려 한다면 "jakarta apache"~10과 같은 형태로 검색을 수행한다.
Range 검색
mod_date:[20020101 TO 20030101]
20020101과 20030101을 포함하여, 이 범위 안에 있는 값들을 가진 mod_date 필드들을 포함하고 있는 문서를 검색한다.
title:{Aida TO Carmen}
이것은 Aida와 Carmen 범위 내에 있는 title을 갖는 문서들을 찾는다. 이 때, Aida와 Carmen은 포함되지 않는다.
[] : 최소값과 최대값을 포함한 Range 검색
{} : 포함하지 않는 Range 검색
Boosting a Term
Lucene은 발견된 term들을 기반으로 문서가 일치하는 정도를 판단하는 기능을 제공한다. term을 boost하려면, 검색하려는 term의 끝에 boost factor (숫자)와 함께 캐럿 기호 "^"를 사용한다. boost factor가 높을수록, term과의 관련성이 더 높아진다.
jakarta ^4 apache : Jakarta 에 boost 적용
Boolean 연산자
연산자들은 반드시 대문자여야 한다.
OR : 디폴트 결합 연산자. 기호 || 를 사용할 수도 있다.
AND : 교집합 연산자. 기호 &&를 사용할 수도 있다.
+ : 반드시 포함되어 있어야 하는 Term을 지정한다. (ex: +jakarta apache) NOT : 차집합 연산자. ! 기호를 사용할 수 있다.
- : 이 연산자는 "-" 기호 다음에 있는 term을 포함하고 있는 문서들은 제외한다. "jakarta apache"는 포함하지만 "jakarta lucene"은 포함하지 않는 문서들을 검색하려면 "jakarta apache" -"jakarta lucene"과 같은 형태의 질의를 사용하면 된다.
Escaping Special Characters
아래와 같은 특수 문자를 escaping하기 위해 문자 얖에 역슬래쉬(\) 문자를 사용한다.
+ - && || ! ( ) { } [ ] ^ " ~ * ? : \
즉 (1+1):2를 검색하려면 \(1\+1\)\:2와 같은 질의를 사용한다.
![]()
( 월간 마이크로 소프트웨어 8월 연재 )
Apache Lucene은 Doug Cutting에 의해 순수 JAVA로 개발된 full-text 검색 엔진이다. 아파치 자카르타의 서브 프로젝트로 개발되어 오다 현재는 아파치 최상위 프로젝트로 승격되었으며, 너치(nutch)라는 자식 프로젝트 까지 갖춘 소위 대박난 오픈 소스 프로젝트 이다. 동급(아파치 프로젝트 레벨)의 다른 프로젝트에 비해 국내 개발자들 에겐 인지도가 무척 저조한 편이라 Lucene이 적용된 레퍼런스 조차 제대로 찾아보기 힘들 지만 Apache Lucene 프로젝트는 나날이 발전 되어서 현재는 C++, C#, Python, Perl 과 같은 여러 다른 언어로도 포팅 되어 널리 이용되고 있다.
------------------------------------------------------------------------------------------
너 치(nutch)는 lucene의 개발자인 Doug Cutting이 역시 수석 개발을 맡아 진행하는 lucene을 기반으로 한 오픈 소스 프로젝트로 구글과 같은 대형 검색 서비스사의 독점을 막고, 누구나 쉽게 사용하고 공유할 수 있는 오픈 소스 검색엔진을 만든다 라는 취지 하에 개발되게 되었고, 2005년 1월 아파치 인큐베이터 프로젝트에 소속되었다가 최근 탑 레벨 프로젝트인 lucene 의 서브 프로젝트로 승격 하게 되었다. (http://lucene.apache.org/nutch/ ) ------------------------------------------------------------------------------------------
1. Lucene의 탄생
Lucene 은 1997년 Doug Cutting의 개인 프로젝트로 시작된 그의 4번째(Xerox, Apple , Excite & Lucene) 검색 소프트웨어 이다 . 믿기지 않는 사실 이긴 이지만 그가 작성한 최초의 자바프로그램 이였다고 하니 수년간이나 자바공부에 전념을 해도 이렇다 할 진전이 없었던 우둔한 필자의 입장에선 부끄러움과 함께 절로 존경심이 생기지 않을 수 없다.
처 음 Lucene을 개발하던 당시에는 이 제품을 상용화 하려던 의도를 가지고 있었다고 한다. 하지만 곧 생각을 바꿔 sourceforge에 공개 함으로서 삽시간에 전세계 개발자에게 퍼지게 되었고 1년여 정도가 지나 아파치 재단에 채택되면서 Lucene은 말 그대로 개발의 날개를 달게 되었다. (실제로 Lucene의 로고는 날개 형상과 매우 흡사하게 생겼다.) 그리고 현재는 아파치 탑 레벨 프로젝트로 승격되었고, 여러 개발 언어로 번역되어 전세계 개발자에게 널리 퍼지면서 나중에 소개할 Luke 와 Limo 같은 서드파티(third-party) 툴까지 마구 양산 되면서 개발자를 날로 즐겁게 해주고 있다.
|
Version |
Release date |
이력 |
|
0.01 |
2000년 3월 |
최초 오픈소스 release ( sourceforge) |
|
1.0 |
2000년 10월 |
|
|
1.01b |
2001년 7월 |
마지막 sourceforge release |
|
1.2 |
2002년 6월 |
Apache Jakarta release |
|
1.3 |
2003년 12월 |
Compound index format, QueryParser 개선, remote searching, token positioning, extensible scoring API |
|
1.4 |
2004년 7월 |
Sorting, span queries, term vectors |
|
1.4.1 |
2004년 8월 |
버그 픽스( sorting performance) |
|
1.4.2 |
2004년 10월 |
IndexSearcher optimization 과 기타 버그 픽스 |
|
1.4.3 |
2004년 겨울 |
기타 수정 |
<표 1> Lucene Release History
2. Lucene 의 활용
검 색엔진 이라 하면 아주 고가의 상용 솔루션을 먼저 떠올리던 시절이 있곤 했다. 하지만 Doug Cutting 과 여러 오픈 소스 개발자들의 노력으로 어느새 모든 개발자들은 문서를 Indexing 하고 Searching 하는 능력을 별다른 노고 없이 ( 솔직히 API를 살펴보는 최소한의 노고는 필요 할 것이다.) 갖출 수 있게 되었다. 이제 이 파워풀 한 능력을 어디에다 써먹을 수 있을까? 기본적인 문서 검색에서 시작해 이메일, CD컨텐츠, xml, 데이터베이스, 웹사이트 등등 무궁무진하게 많은 영역을 다룰 수 있을 것이다. 하지만 여기에도 한계는 있었다. 필자의 경우 공공기관 관련 SI프로젝트 에서 Lucene 검색 엔진을 도입 하려 했을 때 단지 오픈 소스 라는 이유로 혹은 지원이나 문제 발생시 책임 소지 등을 거론하며 냉대 받고 결국은 훨씬 성능이 떨어지면서 사용하기도 불편한 고가의 검색 엔진 솔루션을 구입해서 프로젝트를 진행했던 경험이 있었다.
그 후 다시 기회가 찾아 왔을 땐 구글의 데스크탑 검색과 Lucene.net (Lucene의 닷넷 버전)을 이용한 Microsoft의 email 검색 소프트웨어인 Lookout(그림1) 을 레퍼런스로 들면서 열심히 고객을 설득했고, 결국에 우리팀은 Lucene을 이용해 프로젝트에서 빈번하게 DB접속이 일어나 성능을 저하 시키는 모든 요소를 Lucene 검색엔진 으로 대처 하였고 대용량 DB의 like검색으로 인한 과부하를 적절하게 해소 할 수 있었다.
--Doug Cutting이 제시한 lucene의 인덱싱과 검색을 적용 가능한 일반적인 사례 ---
" 이메일 검색: 저장된 메시지를 검색할 수 있고 새로 도착한 메시지를 새인에 추가할 수 있는 이메일 애플리케이션.
" 온라인 문서 검색: 온라인 문서 또는 저장된 출판물을 검색할 수 있는 CD 기반이나 웹 기반 또는 애플리케이션에 포함된 문서 판독기(reader).
" 웹 페이지 검색: 사용자가 방문한 모든 웹 페이지를 색인화하기 위해 개인 검색 엔진을 만들 수 있는 웹 브라우저 또는 프록시 서버. 이것을 사용하여 쉽게 페이지를 다시 방문할 수 있다.
" 웹 사이트 검색: 웹 사이트를 검색할 수 있는 CGI 프로그램
" 내용 검색: 저장된 문서에서 특정 내용을 검색할 수 있는 애플리케이션. 내용 검색 기능은 문서 열기 대화상자에 통합될 수 있을 것이다.
" 버전 관리 및 컨텐트 관리: 문서나 문서 버전을 색인화해서 쉽게 검색할 수 있는 문서 관리 시스템.
" 뉴스 및 유선(wire) 서비스: 뉴스가 도착했을 때 기사를 색인할 수 있는 뉴스 서버나 릴레이 서버.

< 그림1 > Lucene.Net 으로 개발된 Microsoft의 Lookout 을 설치한 outlook 화면
3. 인덱싱과 검색의 Core 클래스
이제 슬슬 본론으로 들어가 Lucene 검색 엔진을 살펴 보자. Lucene을 요리하기 위해 필요한 재료인 라이브러리와 api 는 http://lucene.apache.org 에서 구할 수 있다.
문서를 인덱싱 하고 검색하기 위해 필요한 핵심 클래스와 절차는 다음과 같다.
<인덱싱 요소>
IndexWriter : 인덱스 파일을 생성하거나 수정(혹은 문서추가)하는 사용되는 클래스
Directory : 인덱스 파일이 저장될 경로를 담는 클래스 이다. IndexWriter 객체의 생성자의 인자로 사용된다.
Analyzer : 문서를 인덱싱 하는 과정에서 다양한 형태로 token을 분리하는 역할을 한다. 역시 IndexWriter 객체의 생성자의 인자로 사용된다.
Document : Field의 조합으로 이루어진 하나의 문서. 데이터베이스 에서 여러 column으로 이루어진 1건의 row 와 비슷한 개념이다.
Field : Document를 구성하는 단위. 데이터베이스에서 하나의 column과 비슷한 개념이다.
위에서 나열한 요소를 가지고 문서를 인덱싱 하기 위해서는 다음과 같은 순서를 따른다.
(1) 인덱스 파일이 저장될 경로 정보를 담는 Directory 객체 생성
(2) 인덱스 요소 분석을 위한 Analyzer 객체 생성
(3) Directory와 Analyzer 를 생성자의 인자로 IndexWriter 객체 생성
(4) Document 객체 생성 후 Document 객체에 필드 추가
(5) IndexWriter 객체에 Document 추가
<검색 요소>
Searcher : 인덱스 파일을 read-only 모드로 열어서 검색하고 결과를 반환한다.
Term : 검색의 기본 단위가 되는 클래스이며, 데이터 베이스 의 질의시 where name='maso' 와 같이 String 요소의 쌍으로 구성되어 있다.
Query : 특정한 검색 포맷을 제공하는 클래스이다. 여러 구현체를 통해 다양한 검색 방법을 제공한다.
TermQuery : Lucene이 제공하는 가장 일반적인 Query 클래스 이다.
Hits : 검색결과를 담는 컨테이너 역할을 한다.
검색 절차
(1) 인덱스 디렉토리 경로를 인자 값으로 해서 Searcher 객체 생성
(2) 인덱스 요소 분석을 위한 Analyzer 객체 생성
(3) 검색을 위한 Query 객체 생성
(4) Searcher 객체의 search(Query query) 메쏘드를 호출하여 검색
4. 문서 인덱싱 및 검색 예제
<리스트1> 인덱싱 예제 (SimpleIndex.java)
package maso.lucene.indexing;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.analysis.WhitespaceAnalyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import java.io.IOException;
public class SimpleIndex {
private void index() throws IOException {
String dirPath =
System.getProperty("java.io.tmpdir", "tmp") +
System.getProperty("file.separator") + "simple-index";
Directory dir = FSDirectory.getDirectory(dirPath, true);
Analyzer analyzer=new WhitespaceAnalyzer(); ---------------(1)
IndexWriter writer = new IndexWriter(dir, analyzer, true);
for (int i = 0; i < 10; i++) {
Document doc = new Document();
doc.add(Field.Text("title", "Lucene 검색 엔진"));
doc.add(Field.Text("content", "Lucene 의 소개 및 간단한 예제를 다룬다. "));
writer.addDocument(doc);
}
writer.optimize();
writer.close();
}
public static void main(String[] args) throws IOException {
SimpleIndex si = new SimpleIndex();
si.index();
}
}
<리스트1>의 예제 코드는 인덱싱 작업을 하는 심플한 자바 프로그램 코드 이다. 지면상 핵심 코드만 추출하였지만 실행 가능한 전체 소스는 '이달의 디스크' 에서 찾아 볼수 있다.
이 예제에서 보는 바와 같이 Lucene을 이용해 인덱싱 하는 작업은 너무나도 간단하다. 먼저 인덱스 파일이 생성될 위치 정보를 담고 있는 Directory 객체와 Text 분석을 위한 Analyzer 객체를 생성 하고 이 두 객체를 생성자의 인자로 가지는 IndexWriter 객체를 이용해 Document를 담기만 하면 되는 것이다. 여기서 눈 여겨 볼 곳은 (1)번 표기가 된 Line의 Analyer 객체의 생성 부분이다. Lucene은 기본적으로 4개의 Built-in Analyzer 를 제공 하는데 이 예제에서 사용된 WhitespaceAnalyzer 와 StopAnalyzer, SimpleAnalyzer, StandardAnalyzer 등이 있다. 각각의 용도 및 특징은 다음 단원에서 좀더 세부적으로 알아보도록 하고, 여기에서 사용된 WhitespaceAnalyzer 가 공백 단위로 텍스트를 파싱 한다는 것 정도만 알고 넘어가자. 마지막으로 IndexWriter를 이용해 Document 를 저장한 후 프로그램을 반드시 호출해 줘야 하는 메소드가 있는데 예제 샘플의 마지막 두 라인에서 와 같이 optimize() 메쏘드와 close() 메소드가 있다. Close() 메쏘드는 index 파일의 변경된 내용을 적용시키고 관련된 모든 파일을 닫는다. 그리고 optimize() 메소드는 생성된 여러 인덱스 요소들을 하나로 묶는 기능을 수행한다. Optimize() 부분은 인덱스 튜닝과 연관되어 복잡하고 많은 내용을 담고 있으므로 다음 연재 에서 좀더 상세하게 다룰 것이다. '이달의 디스크'에서 전체 소스를 받아서 실행시켜 보면 시스템의 Temp 디렉토리( 일반적으로 C:\tmp )에 인덱스 파일이 생성되는 것을 볼 수 있을것이다.
<리스트2> 인덱스 검색 예제 (SimpleSearcher.java)
package maso.lucene.searching;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.Searcher;
import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.queryParser.ParseException;
import java.io.IOException;
public class SimpleSearch {
public Hits search() throws IOException, ParseException {
String dirPath =
System.getProperty("java.io.tmpdir", "tmp") +
System.getProperty("file.separator") + "simple-index";
Searcher searcher = new IndexSearcher(dirPath);
Analyzer analyzer=new SimpleAnalyzer();
String queryString="검색";
String defaultField="title";
Query query = QueryParser.parse(queryString,defaultField,analyzer); ----------(1)
System.out.println("query=="+query.toString());
Hits hits= searcher.search(query); ---------------------(2)
searcher.close();
return hits;
}
public static void main(String[] args) throws IOException, ParseException {
SimpleSearch ss=new SimpleSearch();
Hits hits=ss.search();
int ctn=hits.length();
System.out.println(ctn+"건의 문서가 검색 되었습니다.\n");
for(int i=0;i<ctn;i++){
System.out.println(i+"번째 : "+hits.doc(i).get("title"));
}
}
}
<리스트 2> 는 <리스트1>과 마찬가지로 인덱스 파일을 검색하는 자바 프로그램의 핵심 코드만 추출한 예제 이다. 검색 과정을 살펴 보면 먼저 인덱스 파일 경로 정보를 가진 IndexSearcher 객체를 생성하고 (Searcher 클래스는 IndexSearcher 와 MultiSearcher, ParallelMultiSearcher 등이 있다.) (1) 표기 가 있는 라인 에서와 같이 검색할 query를 생성해서 (2)표기 라인에서 Hits 객체에 query 검색 결과를 담는다. (1)번 라인에서 QueryParser 에 의해 생성된 query는 Query 객체의 toString() 메쏘드를 호출하면 출력해볼수 있는데 query= ' title: 검색' 과 같은 단순한 구조 이다. 사족을 덧붙일 필요도 없겠지만 title 필드에서 '검색' 이라는 단어를 포함하는 문서를 찾는다 라는 의미 이다. 검색을 위해 필요한 핵심 클래스인 Searcher 와 Query 에 대한 내용도 다음 연재에서 보다 상세하게 다룰 것이다. 인덱싱 예제와 마찬가지로 검색 프로그램 에서도 반드시 Searcher 객체를 close 시켜야 하지만 Searcher 객체는 스레드에 안전하므로 성능을 위해서 오브젝트 풀링 기법을 사용하거나 싱글톤 패턴을 적용해 close 시키지 않고 재사용 하는 것도 무방하다.
<리스트2> 예제에서는 마지막 라인에서 Hits 객체를 return 시키고 끝나는데 '이달의 디스크'를 통해 전체 소스를 받아 보면 반환된 Hits 객체에서 검색된 문서의 수와 검색결과를 출력하는 예제를 볼 수 있을 것이다.
<부가설명2>
----------------------------------------------------------------------------------------------
오브젝트 풀링과 싱글톤 패턴에 대한 내용은 최범균님의 javacan 사이트에 방문 하시면 잘 정리된 기사를 찾아 보실 수 있습니다.
오브젝트 풀링 : http://javacan.madvirus.net/main/content/contentRead.jsp?contentNo=7&block=4
싱글톤 패턴 : http://javacan.madvirus.net/main/content/contentRead.jsp?contentNo=5
----------------------------------------------------------------------------------------------------------
5. Lucene 의 built-in Analyzer
Luene에서 Analyzer는 크게 2가지 용도로 사용되는데 첫번째는 인덱싱 작업에서 문서를 필드 형태로 나누는데 사용이 되며, 두번째 용도로는 검색시 쿼리를 파싱하는데 사용된다. Lucene에서 이미 만들어진 4가지 built-in Analyzer를 제공 하는데 WhitespaceAnalyzer, StopAnalyzer , SimpleAnalyzer 그리고 StandardAnalyzer 등이 있다. 아래 <표2>을 통해 각각의 특징에 대해서 살펴 보자.
|
Analyzer |
특징 |
|
WhitespaceAnalyzer |
스페이스를 구분으로 token을 분리한다. WhitespaceTokenizer 사용 |
|
SimpleAnalyzer |
Letter를 구분으로 token을 분리한다. LetterTokenizer 와 LowerCaseFilter 사용 |
|
StopAnalyzer |
Letter를 구분으로 token을 분리하고 , 중지단어를 token에서 제거한다. LetterTokenizer , LowerCaseFilter , StopFilter 사용 |
|
StandardAnalyzer |
|
다음은 "AB&C 한글 aaa@gmail.com" 이라는 문장을 <표2>에 나온 각각의 Analzer로 인덱싱 한 결과 이다.
a. WhitespaceAnalyzer : [AB&C] [한글] [aaa@gmail.com]
b. SimpleAnalyzer : [ab] [c] [com] [gmail] [한글] [aaa]
c. StopAnalyzer : [ab] [c] [com] [gmail] [한글] [aaa]
d. StandardAnalyzer : [ab&c] [aaa@gmail.com]
그럼 이제 각각의 Analyzer에 대해 하나씩 알아보자. 먼저 WhitespaceAnalyzer 는 lucene의 4가지 built-in Analyzer 중 가장 심플한 Anaylzer 로서 단지 스페이스 단위로 token을 분리한다. 그 다음 SimpleAnalyzer는 Letter 단위로 문자를 나누기 때문에 공백이나 물론 특수문자는 제외되고 가장 많은 token으로 분리되며, LowerCaseFilter를 사용하므로 대문자는 모두 소문자로 변환된다. 나누어진 token 결과가 다른 Analyzer 보다 많으므로 인덱싱후 index파일의 크기 역시 가장 클 것이다. 그리고 다음 StopAnalyzer는 기본적으로 SimpleAnalyzer와 동일한 기능을 가지기 때문에 결과값 역시 동일하다. 다만 StopFilter를 사용해서 검색에 제외될 항목들 가령 and, an, if, else 같은 특정한 항목들을 지정해서 제외 시킬 수 있으므로 인덱싱이나 검색에 소요되는 시간과 인덱싱 파일의 용량을 효율적으로 줄 일수 있다. 마지막으로 StandardAnalyzer 가 있는데 다양한 문법 기반 하에 토큰을 분리하는 데다 StopAnalyzer와 같이 StopFilter를 사용하므로 다른 built-in Analyzer에 비해 가장 기능이 뛰어난 Analyzer 라고 볼 수 있다. 하지만 위의 인덱싱 결과에서 처럼 아쉽지만 한글과 같은 비 영어권 문자는 기본적으로 인식하지 못한다. 하지만 StandardAnalyzer가 기본적으로 사용하는 StandardTokenizer의 소스를 수정하거나 Lucene의 SandBox에 위치한 CJKAnalyzer(org.apache.lucene.analysis.cjk.CJKAnalyzer)를 사용하면 충분히 처리가 가능하다.
( SandBox : http://lucene.apache.org/java/docs/lucene-sandbox/ )
6. Lucene 관련 유용한 유틸리티
이번 단원에서 소개할 내용은 lucene 관련 유용한 third-party 유틸리티 이다.
Luke
가장 먼저 소개할 유틸리티는 아래 <그림2>에 나와 있는 인덱스 브라우저 Luke 이다. Lucene은 이진파일로 된 index파일을 사용하므로 언어에 관계없이 index파일을 읽을 수 있는데 이 luke 라는 유틸리티를 사용하면 마치 데이터베이스 관련 GUI 툴을 보듯 index파일의 내용을 일목요연 하게 볼 수 있으며 검색 기능도 제공한다. (http://www.getopt.org/luke/ 에서 찾아볼수 있다.)

<그림2> 인덱스 브라우저 Luke
Lucli
Lucli는 Dror Matalon에 의해 배포되고 있는 Lucene의 Command Line 인터페이스 이다. 문서를 인덱싱 하기 위해 굳이 코드를 작성하지 않더라도 이 Lucli 를 사용하면 쉽게 문서의 인덱싱이 가능하다. Lucene의 SandBox에서 구할수 있으며, 관련 jar파일을 클래스 패스로 지정한 후
$JAVA_HOME/bin/java lucli.Lucli 명령을 실행하면 된다.
아직은 작성된 Document 도 없으며, 인덱싱 시에 StandardAnalyzer를 사용하도록 하드 코딩 되어 있으므로 실제 사용 시에 약간의 제약은 따른다.
Limo
Limo는 Julien Nioche가 개발한 lucene Index Monitor 이다. http://limo.sourceforge.net 에서 다운로드 받을 수 있으며 limo.war 파일을 ServletContainer 에 올려서 바로 사용 가능하다. 톰캣의 경우엔 $TOMCAT_HOME/webapps/ 폴더에 .war 파일을 복사한다.
이 제 서버를 실행하고 limo Application을 웹브라우저로 실행시켜 보자. Index 파일의 경로를 지정하는 폼 화면이 나온 후 경로를 적당히 지정해주면 아래 <그림3> 과 같은 화사한 웹 화면을 감상 하실 수 있을 것 이다. 물론 기본적으로 한글이 깨져서 나올 테지만 jsp 상단의 contentType 부분에 "charset=euc-kr" 을 추가해주면 한글 출력도 문제 없다. ( <%@page contentType="text/html;charset=euc-kr"%>)
Limo는 Index 파일의 정보를 일목요연 하게 보여주며, 부가적으로 인덱스 파일의 검색 기능도 제공한다. Luke와 비교해 각각 일장 일단이 있으므로 각각 한번씩 비교해 보기 바란다.

<그림 3> Limo Application의 실행 화면
5. 결론
이번 연재 에서는 Lucene의 실전 활용 보다는 멋진 오픈 소스 검색엔진의 소개가 주 목적 이였기에 복잡한 내용은 최대한 배제하고 소개 글과 함께 기본 기능에 대해서만 간략하게 다루어 보았다. 다음 연재 에서는 Analyzer 의 보다 상세한 내용과 인덱스 튜닝에 대해 다루어 볼 예정이며 고급 검색 기법과 실전에 쓰일 만한 여러 가지 문서 포맷의 인덱싱 그리고 실제 Lucene의 적용시 격게 되는 여러 가지 문제점과 해결책에 대해 보다 심도 있게 다루어 보도록 하겠다. 지면상 광범위한 내용 전체를 전부 다룰 수가 없으므로 조금 아쉬움이 남기는 한다. 이번 기사에 부족함을 느끼는 독자들은 Apache Lucene 웹사이트와 wiki를 방문하면 다양한 레퍼런스를 포함해서 좋은 정보를 많이 얻을 수 있을 것 이다.

가족이 필요해 3부
흠....예고는 하면 안되는건지 애청자를 위해서는 해야 하는건지는 잘 모르겠지만
에라 나도 모르겠다 일단 궁금증과 기대감은 부풀려 보자 꾸나 ㅋㅋㅋㅋㅋㅋ
짧고 굵게 올리겠다
놀라지 마라!!! 가인에게 동생이 생긴다 뜨아~!!
2회 방송에도 조용한 날이 없던 가족에게 또 한명더? 게다가 막둥이라고??
오마이갓~~~ 거기다가 이 애가 나온다고 뜨아~~~~~~~~

부득이하게 방송 저작권 및 관계자의 요청으로 출연자의 얼굴을 모자이크 처리했다 -_ㅜ
아무튼 기대해도 좋다
이번주 화요일 8월 5일 화요일 늦은 11시 기대하라 두둥~

한가하고 조용하던 가족에 청소 바람이 분다 ㅋㅋ
갑작스런 엄마의 청소 요구에 다들 불만은 터지지만 부지런히 청소를 진행한다.
청소 후... 갑작스럽게 들이닥친 가인들의 친구들 브아걸

엄마는 갑작스런 친구들 방문에 딸에게 핀잔을 주고 구박을 하는데 ㅋㅋㅋ
이에 딸 친구들은 아버지와 오빠에게 노래선물을 한다 ㅋㅋㅋ
아버지는 딸친구들의 무대를 구경하고 돈벌이를 위해(?) 출근(?)을 하고
심심하던 엄마와 오빠, 딸, 딸친구들은 마당에 나가서 놀이를 시작하는데
국민 놀이인 끝말잇기 ㅋㅋㅋ 가인 왜그래~ 룰도 모르는거냐?? 첫판부터 걸려서
엉덩이로 이름을 쓴다

이윽고 아빠의 퇴근시간이 되고 아빠는 1회때의 한일까 ㅋㅋㅋ 못먹은 추어탕을
먹기위해서 미꾸라지를 사오고 아빠의 퇴근으로 부터 절정에 다다른다 ㅋㅋㅋ
미꾸라지는 모녀에게는 큰 무서움이 되고 아버지는 태연하게 요리를 하는 척(?) 하는데
추어탕을 고추장으로 끓이나? ㅋㅋㅋ

그래도 새롭게 얻은 시직하나.... 생(生) 미꾸라지를 요리하기 전에는 냄비 또는 그릇에
담고 소금을 집어넣어 미꾸라지의 거품(?)을 빼도록 하라
엄청난 시간이 소요되고 온갓 재료가 들어간 추어탕이 완성되고 가족들은
(2회만에 나오는)식탁에 앉는데 아니나 다를까 성인 가운데 손까락 만한 미꾸라지를
아무렇지도 않게 먹는 아빠 가인에게도 건네는데 -_-
가인아 아무리 방송이지만 너무 리얼리티다 -_- 가족을 위해서 미꾸라지를.....

미꾸라지에 대해 인터뷰는 했지만 특별히 방송 후문을 알려주겠다.....
가필 작가가 들은 말은 아래와 같다(작가 싸이월드에서 발췌) ㅋㅋㅋ (특별 서비스~)

읔....정말 나도 못먹을거 같은 추어탕이였는데 ㅋㅋㅋㅋ
아무튼 가족이 한 식탁에서 밥 먹는걸 보니 나도....쩝..... 그립다.....
Shell
- 사용자와 운영체제 사이에 존재하여 사용자의 명령을 운영체제가 이해하도록 하고, 사용자 명령의 실행 결과를 사용자에게 보여주는 사용자 인터페이스
- Steven Bourne이 개발한 Bourne Shell(sh)가 최초의 Shell 이다.
Bash Shell
- 1988년 1월 10일 Brian Fox가 개발
- GNU 시스템의 표준 Shell로 자리 잡았고 그 후 거의 모든 유닉스에서 사용됨
- 1989년 Chet Ramey가 합류하여 곧 공식적으로 bash의 유지보수를 맡게 되었다.
- Sh Shell의 기본기능에 csh와 ksh의 장점을 합하여 bash가 탄생하였다.
Bash 기본 설정 파일
- .profile : sh의 설정파일
- 대부분의 환경 설정이 이루어 지며 사용자가 시스템에 로그인할 때마다 실행된다.
- .bash_profile : bash의 .profile
- .bashrc : 서브Shell이 실행될 때 읽는다.
- 서브 Shell이란 로그인Shell에서 다시 bash가 실행되는 경우이다.
Shell script
- Script : Shell 명령어들을 담고 있는 파일로 Shell Program이라고도 부른다.
- .bash_profile, .bashrc 등은 모두 script이다.
문법
변수
- 처음 사용될 때 만들어진다. 즉, 미리 선언할 필요가 없다.
- 유닉스 명령과 마찬가지로 대소문자 구별이 있다.
- 기본적으로 데이터를 문자열로 저장한다. 수치를 입력해도 문자열로 저장한다.
- 계산이 필요한 경우에는 자동으로 수치로 변환하여 계산 후 다시 문자열로 저장된다.
- 변수의 값을 사용할 때는 변수 명 앞에 “$”를 붙여서 사용한다.
foo=”동영상은 tv팟” - 입력 echo $foo - 입력 동영상은 tv팟 - 출력결과
- 주의! 변수에 값 입력시 ! 가 들어갈시에는 작은따옴표(‘test’)로 입력한다.
환경변수
- Shell을 기동하고 나면 기복적으로 셋팅 되어 있는 변수. 필요한 경우 일반변수처럼 값을 얻어오거나 셋팅 할 수 있다.
- $0 – 실행된 쉘 스크립트 이름 b. $# - 스크립트에 넘겨진 인자의 개수 c. $$ - 쉘 스크립트의 프로세스 ID
인자변수
- 쉘 스크립트에 인자를 넘겨줄 때 그 인자들에 대한 정보를 가지고 있는 변수이다.
- $1 ~ $nnn – 넘겨진 인자들 b. $* - 스크립트에 전달된 인자들을 모아놓은 문자열 하나의 변수에 저장되며 IFS 환경변수의 첫번째 문자로 구분된다. c. $@ - $*와 같은 기능이지만 구분자가 IFS변수의 영향을 받지 않는다.
예제 -> ./vi test2.sh echo "This Script Executable File : $0" echo "Argument Count : $#" echo "Process ID : $$" echo "Argument List \$* : $*" echo "Argument List \$@ : $@" echo "Argument 1 : $1" echo "Argument 2 : $2" -> ./sh test.sh a b This Script Executable File : ./test2.sh Argument Count : 2 Process ID : 9308 Argument List $* : a b Argument List $@ : a b Argument 1 : a Argument 2 : b
함수
- 함수는 스크립트 안의 스크립트이다 (a script-within-a-script)
- 함수는 쉘의 메모리에 저장되고, 실행 속도가 빠르다
- declare –F 명령어로 현재 자신의 로그인 세션에 정의되어 있는 함수들을 알 수 있다.
- 명령어 우선순위
- Alias (alias ls=’ls –l’) b. 예약어 (function, if , for, ….) c. 함수 d. bunlt-ins like cd and type e. 스크립트, 프로그램
함수 정의 방법
bash
function testfunc {
echo "test"
}
sh
testfunc() {
echo "test"
}
예제)
val1=$1
val2=$2
function testfunc {
echo "동영상은 tv팟"
echo $val1
echo $val2
}
testfunc
}
String 연산자
- ${varname:-word} : varname이 존재하고 null이 아니면 그 값을 리턴, 아니면 word리턴
- ${varname:=word} : varname이 존재하고 null이 아니면 그 값을 리턴, 아니면 varname에 word를 대입
- ${varname:?message} : varname이 존재하고 null이 아니면 그 값을 리턴, 아니면 varname을 출력하고 message를 출력
- ${varname:+word} : varname이 존재하고 null이 아니면 word를 리턴 아니면 null을 리턴
- ${varname:offset:leng(없으면 varname의 length)} : varname=daum tvpot이면 ${varname:4}의 값은 tvpot, ${varname:5:2}의 값은 tv
pattern and pattern matching
- ${#valiable} : valiable의 길이를 가져온다
- ${variable#pattern} : pattern이 variable의 앞부분이 일치하면 가장 짧은 부분을 제거하고 나머지를 리턴
- ${variable##pattern} : pattern이 variable의 앞부분과 일치하면 가장 긴 부분을 제거하고나머지를 리턴
- ${variable%pattern} : pattern이 variable의 뒷부분과 일치하면 가장 짧은 부분을 제거하고나머지를 리턴
- ${variable%%pattern} : pattern이 variable의 뒷부분과 일치하면 가장 긴 부분을 제거하고나머지를 리턴
- ${variable/pattern/string} : 일치하는 가장 긴 부분을 string으로 대체. 한번만 일어남
- ${variable//pattern/string} : 일치하는 가장 긴 부분을 string으로 대체. 모두 일어남
조건문
if / else
문법
if condition
then
statements
elif condition
then
statements
else
statements
fi
값 비교절
- [ string ] - string이 빈 문자열이 아니라면 참
- [ string1 = string2 ] - 두 문자열이 같다면 참 or string1 matches string2
- [ string1 != string2 ] - 두 문자열이 다르면 참 or string1 does not match string2
- [ -n string ] - 문자열이 null(빈 문자열) 이 아니라면 참
- [ -z string ] - 문자열이 null(빈 문자열) 이라면 참
- [ expr1 -lt expr2 ] – exp2가 exp1보다 크면 참 (‘Less than')
- [ expr1 -le expr2 ] – exp2가 exp1보다 크거나 같다면 참 (‘Less than or equal')
- [ expr1 -eq expr2 ] - 두 표현식 값이 같다면 참 (‘EQual')
- [ expr1 -ne expr2 ] - 두 표현식 갑이 같지 않다면 참 ('Not Equal')
-
[ expr1 -gt expr2 ] - expr1 > expr2 이면 참 ('Greater Then')
-
[ expr1 -ge expr2 ] - expr1 >= expr2 이면 참 ('Greater Equal')
- [ expr1 -ne expr2 ] - expr1 != expr2 이면 참 ('Not Equal')
- [ ! expr ] - expr 이 참이면 거짓, 거짓이면 참
- [ expr1 -a expr2 ] - expr1 AND expr2 의 결과 (둘다 참이면 참, 'And')
- [ expr1 -o expr2 ] - expr1 OR expr2 의 결과 (둘중 하나만 참이면 참, 'Or')
파일관련 비교절
- [ -d FILE ] - FILE 이 디렉토리이면 참
- [ -e FILE ] - FILE 이 존재하면 참
- [ -f FILE ] - FILE 이 존재하고 정규파일이면 참
- [ -r FILE ] – 파일 읽을 권한이 있다면 참
- [ -s FILE ] – 파일이 있고 빈파일 아니라면 참
- [ -w FILE ] – 파일 쓰기 권한이 있다면 참
- [ -x FILE ] – 실행권한이 있다면 참
- [ -O FILE ] – 파일의 주인(?)이라면 참
- [ -G FILE ] – 파일의 group ID와 사용자의 group ID가 같다면 참
- [ FILE1 -nt F - : FILE1이 FILE2 보다 새로운 파일이면 ( 최근파일이면 ) 참
- [ FILE1 -ot F - : FILE1이 FILE2 보다 오래된 파일이면 참
case
문법
case 변수 in
pattern 1 )
statements ;;
pattern 2 )
statements ;;
* )
statements ;;
esac
select
문법 select name [in list] do statements that can use $name … done

가족들 처음 만나다

가장먼저 도착한 사람은 김흥국! 그의 손에 들려진건 몇가지 옷과 축구공 (솔직히 거의 축구장비였다)
거의 동시에 도착한 모녀 김청과 가인! 가인은 차에서 내리자 마자 뜨아~! 자기만한 개(쿠키)를 보고
겁을 먹었다....(실제로 가인은 개를 무서워 한다고 한다)
아들을 뺀 3명의 가족이 모이고 도란도란 이야기를 나눴다. 가인이 선물한 쫄티와 바지를 입은 아빠 ㅋ
먼저 큰웃음을 주시고 ㅋㅋㅋ

일단 밥은 먹어야 하기 때문에 장을 보러 마트로 가는 가족 ㅋ
월남쌈을 먹어야겠다는 엄마, 뭐니뭐니해도 매운탕이 최고라는 아빠 ㅋ 가인은 아빠의 돌출행동에 많이
부끄러워 한다 ㅋㅋ
장을보고 아빠는 돈을 벌기위해 일을 나가고 엄마와 딸만 있을때 이때 오빠가 도착을 하는데...
늦게온 아들을 보고 엄마는 갑작스레 미션을 시킨다 미션 : 밥을 할 쌀을 구하라!!! 아들 도착하자마자
밥솥을 들고 쌀을 구하러 가는데 이게 왠떡? 다된 밥을 파는 가게가 있구나 ㅋㅋㅋ 아들 여유있게
삶은 계란도 먹고 밥을 가지고 집으로 도착하니 거의 금의환향 수준이다 ㅋㅋ 늦게 왔지만 한번에
엄마의 사랑을 받게 되고 저녁찬을 위해 아들은 자신만만하게 낚시를 제안하고 나서는데...
자신만만한 모습은 어디가고 실적은 꽝이다. 아빠의 매운탕은 어떻게 준비를 하나 ㅜㅜ
역시 요즘은 좋아 매운탕도 끓여서 팔잖아? 매운탕을 사서 교묘하게 잡아서 끓인척 하고
아빠와의 저녁을 준비한다. 처음 가족이 모인 저녁 자리라 술도 한잔 하고 매운탕을 먹으면서
가훈도 정하고 즐거운 시간을 보내고 첫날밤(?)을 보낸다....

자다가 갑자기 딸을 깨우는 아빠 윽....잘 보이고 싶은 마음에 아빠를 따라 나서기는 하는데....
갑자기 아침운동을 나가는 아빠 아침잠 많은 딸은 죽기 일보 직전이다... 아니나 다를까 들어오자 마자
침대에 다시 쓰러지는 딸....ㅋㅋㅋ 잘보이는것 보다 잠이 먼저래~ ㅋㅋㅋ 넘흐 귀여워~
과연 이 가족은 무사히 살아갈 수 있을까??
궁금한가? 7월 29일 화요일 늦은 11시 MBC 에브리1을 시청하라

이에 새로운 가족을 이루는 내용으로 도전장을 낸 MBC 에브리원의 '가족이 필요해'(이하 가필)가
7월 22일(화요일) 늦은 11시 첫방송을 한다.
출연진도 적지않게 화려하다.
위의 내용말고 실제 알려진 내용으로는 막 들이대는 아빠 흥국, 철없는 엄마 김청, 사고뭉치 아들 이정,
까칠한 딸 가인으로 나온다고 한다.
공식홈페이지(http://www.mbcevery1.com/variety/only.asp?p_num=237)에서 스틸컷을 뽑아봤다
사진의 초상권 및 저작권은 MBC 에브리원에 있음을 알려드리며 불펌시 법에 접촉될 수도 있음을 알려드림다




40이 넘은 나이에도 아직(?) 소녀이고 싶은 철없는 김청 컨셉보다는 실제 생활에 가까운듯 ㅋ
만능 재주꾼 이정, 능청스럽고 사고뭉치 뻔뻔한 이정 ㅋ
스타킹걸, 마스카라걸 확실한 V라인의 가인 ㅋ
실제 김청의 애완견 쿠키 적지않은 반전을 내줄거 같은놈이야~ ㅋ
이사람들이 가족이 된다니.... 리얼 버라이어티의 침체기에 가상버라이어티가 대세라고는 하지만
M본부의 우결, S본부의 이름도 모르겠다 -_-;; 와 비교하면 리얼에 이제 시작인 방송으로는 케이블이긴 하지만
출연자와 방송 컨셉은 강하다. 실제 우리가 가족을 이루면서 겪을법한 애기와 독특한 가족들의 생활을
동시에 볼 수 있어 한층 더 기대가 된다.
개인적인 바람이 있다면 우리 tv팟(http://tvpot.daum.net/)에서도 가필을 볼 수만 있다면....ㅜㅜ

참취작가 대박 기원한다.
가인아 쌩얼 동영상은 우리 잘 못이 아냐~ 이번 방송으로 안티 많이 없어지고 팬들만 늘어나길 기원할께~
건전한 동영상 사이트 다음 tv팟(http://tvpot.daum.net/)에서 게임동영상 전용 게임섹션(http://tvpot.daum.net/game/Top.do)을 오픈하였다.
스타크래프트 리그 생중계로 스타 매니아층의 사랑을 받아오던 tv팟은 전문 게임 동영상을 볼 수 있도록
한것이다.
사이트를 들여다 보자꾸나 (http://tvpot.daum.net/game/Top.do)
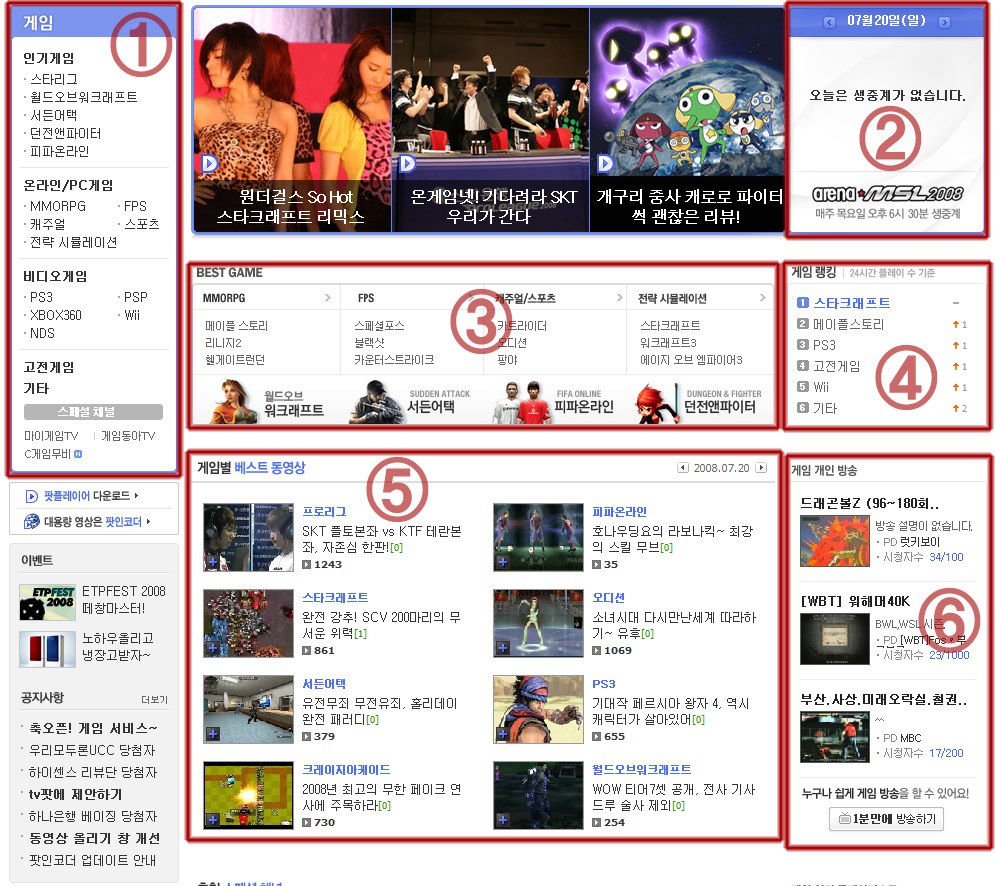
① 게임메뉴
게임섹션의 메뉴이다. 사용자들이 즐겨찾는 인기게임과 온라인/PC게임의 장르별 분류, 비디오 게임의
하드웨어별 구분이되어 찾아보기 쉽도록 구분하였다.
② 스타리그 중계일정
현재 진행되고 있는 e-sport 스타크래프트 리그의 중계일정을 보여준다. 일자옆의 화살표 버튼으로
이전, 이후의 중계일정을 쉽게 볼수 있다.
③ BEST GAME
인기게임을 장르별로 구분하여 빠르게 해당게임 리스트로 갈 수 있도록 링크해 두었다.
④ 게임랭킹
실제 사용자들이 많이 찾아본 동영상의 게임을 랭킹을 볼 수 있다.
⑤ 게임별 베스트 동영상
볼만한 동영상을 바로 볼 수 있도록 재미있는 동영상을 제공하는 메뉴이다
⑥ 게임 개인 방송
팟플레이어에서 실제 방송되고 있는 게임관련 방송을 보여준다. 클릭하면 팟플레이어로 바로 볼 수 있어
편리하다.
이 외에도 게임 및 장르별 페이지에서 베스트동영상과 최신 동영상들을 볼 수 있다.
또한 클립뷰페이지(동영상보는 페이지)에서도 게임관련 링크와 스타리그 중계일정을 볼 수 있다.
우리나라 게임 매니아들의 많은 사랑을 받기 바란다.
뜬금없이 현재 관심분야와는 달리 취업에 관한 글을 쓰게 되었다...
대학생들이 방학에 들어가고 2학기를 맞으면서 취업에 대한 관심들이 또 많아질 수십만 신입
취업희망자들에게 저의 방법을 알려드리고 희망을 줬으면 한다...(후배들이 너무 많이 물어온다)
먼저 글을 읽기전에 흔히 애기해는 수도권대, 일류대, 유명대생들은 제 애기가 전혀 와닿지 않을수
있으니 다른글을 보셔도 무관하며 보시고 비관 및 악성댓글은 삼가하시기 바란다.
뭐가 잘나서 취업에 대한 글을 쓰냐라고 하시는분이 있을지 모르지만 잘나서 쓰는것도 아니고
잘됐다고 쓰는것도 아니다. 이런 사람도 있다고 알려주는것이다.
이 글은 누가 도움이 될까?
앞에서도 애기했듯이 알아주는(?) 대학의 출신 취업희망자들은 그닥 도움이 안될거 같다
왜냐면 필자는 속된말로 애기하는 3류 지방대 출신으로 준비했기 때문이다.
모든 취업자들이 희망을 가지고 힘내길 바란다.
언제부터 취업 준비를 해야 하는가?
필자는 군 전역후 3학년 부터 취업의 힘듬을 알고 준비했다. 그리고 필자는 일찌감치 프로그래머의 길을
생각해고 있었기 때문이다.
필자가 가장 좋다고 생각하는 시기는 대학교 2학년이다. 왜냐면 가장 선택의 길이 많고 3년간 준비하면
못 들어가는 회사가 없다고 생각하기 때문이다.
_M#]
_M#]
_M#]
정보는 어디서 구하는가?
수 많은 채용사이트와 정보카페, 클럽등이 무수하게 많다. 필자는 약 6개의 리크루트 사이트와 약 2개의 채용
관련 카페에 가입하여 준비했다.
리크루팅 사이트
ㆍ사람인(http://www.saramin.co.kr/) 공채달력을 제공하며 보기쉽고 알차다
ㆍ 잡코리아(http://www.jobkorea.co.kr/) 가장 크고 유명한 채용관련 사이트라 생각한다.
ㆍ 커리어(http://www.career.co.kr/) 여러 포털사이트와 재휴되어 운영되는 채용 사이트이다.
ㆍ 인크루트(http://www.incruit.com/) 커지고 있고 많은 행사정보도 올라오는 사이트이다.
ㆍ 알앤디잡(http://www.rndjob.com/index.asp) 이공계 전문 취업사이트이다.
ㆍ 스카우트(http://www.scout.co.kr/) 크지는 않지만 기업제휴가 상당한듯 한 사이트
ㆍ 리크루트(http://www.recruit.co.kr/) 생긴지 얼마 안되는 최초 취업포털이다
ㆍ 커리어젯(www.careerjet.co.kr) 감사하게도 본인에게 직접 추가를 요청한 검색 사이트이다 ^^
카페
ㆍ 취업 뽀개기(http://cafe.daum.net/breakjob) 취업카페 중 가장 유명한 사이트이다.
어느 사이트보다 많은 정보가 넘처 흐르고 같은 취업자들과 정보 공유가 최 강점이다.
이력서, 자소서는 어떻게 쓰는가?
자소서를 써본분들은 다 안다. 자소서 쓸때는 느낀다 '글쓰기가 제일 힘들다', '소설을 써야한다'
특히 공대출신 취업자들은 몇번이나 머리를 쥐어 뜯었을것이다.
실제로 본인의 신상명세인 기본이력서 작성에는 힘들지 않을것이다. 다만 주의 할 점은 제발 자격증에
운전면허증은 기재를 하지 않아도 된다는 점을 애기하고 싶다(운전관련 취업자들은 제외)
또 하나! 자기의 얼굴을 가지고 장난치지는 마라...실제로 이력서 사진을 보고 면접장에서 보면 못알아
보는 사람도 허다하다고 한다. 너무 심하게 꾸미진 말자
그럼 자소서는 어떻게 써야 하는가?
너무 많은것을 다 애기해줄수는 없는게 아쉽다.. 만나서 듣고싶은분은 메일을 쓰던지 답글을 달라 ㅋ
홍대서만 만났으면 한다- ㅋㅋㅋ
신입의 경우 항목에 맞는 글을 자신의 경험에 빚추어 대답을 하라고 애기하고 싶다 지루하고 딱닥한 글은
아무리 마음좋은 인사담당자도 전부 읽기가 힘들다
서두에 결론 또는 짧막한 줄임말을 애기하고 뒤에 설명을 하라....서말에 다시한번 강조하는것도 좋다...
또! 성장과정에 "저는 198?년 ?월 ?일 어디서 누구의 몇남 몇녀중...." 이건 진짜 80~90년대나 쓰던 멘트다
실제로 자소서 컨설팅을 받아보면 요즘에도 이런거 쓰는사람있네? 라는 반응을 받는다 주의하자....
자소서는 어떻게 써라는 답을 주지 못한다 가장 좋은 방법은 최근에 취업문을 두드려본 선배나 친구등의
도움을 받자 부끄럽다 생각하지말라 누구나 자기가 쓴글은 부끄러워 하지만 취업하면 부끄러움은 기억나지
않는다!
면접은 어떻게 보나??
필자는 대기업 2군데, 중견(?)기업 2군데, 벤처기업 8군데 가량 면접을 보았다. 자랑은 아니지만 모두 면접에
통과했고 면접없이 입사제의도 2군데 가량 받았다 (물론 중소, 벤처기업) 재수 없다 생각말라 이젠 희망이다
필자는 얼굴 보통도 아니고 평균이하에 호감형 스타일도 아니다 면접가서 첫인상으로 나보다 못한사람은
거의 못봤다. 그럼 어떻게 10군데 가량의 면접을 다 통과하게 되었는가??
면접은 말빨과 신뢰감이라고 생각한다.
면접은 어떻게 이루어 지는가?
면접에서는 자세와 대답형태, 복장이 기본이라고 생각된다.
면접의 자세라하면 앉는 자세 너무 많이 알려졌지만 군대 차렷자세에서 약간 편하게 앉은 자세라 생각하면
된다. 복장은 요즘은 자유복장을 추구하는 회사도 많지만 필자는 모두 정장면접을 봤다. 가장 깔끔해 보이고
면접자가 "왜 자유복장인데 정장을 입었냐?" 라는 질문을 한다면 "면접관님과 첫 대면을 하는데 자유로운
복장보다는 깔끔하고 정결해 보이는 정장을 입는게 좋다고 생각했습니다" 라고 말하면 된다고 생각했기
때문이다.
대답형태는 남자라면 아니 여자분이라도 격식있는 군대서 쓰이는 "다,나,까" 대답형태가 가장 좋다고 생각한다
실제로 면접에 들어가보면 사투리나 XX했구요- XX 했는데요- 라고 말하는 사람도 태반이다.
면접도 마찬가지다. 자소서와 마찮가지로 자신의 경험과 정보력을 동원해서 대답을 하는것이 좋다.
대부분의 회사는 면접 막바지에 질문시간을 준다. 이때는 해당 회사에 대한 질문을 하는것이 좋다 그후 더 좋은
정보를 얻기 위해서는 회사 복지에 대해서 질문 하는것이 좋다.
마치면서....
주저리 주저리 많은 글을 썼지만 실제로 취업희망자들은 현실적으로 다가오질 않을것이다.
가장 추천하는 방법은 주위사람들의 도움이나 동아리, 카페들을 적극활용해서 정보를 공유하라는 것이다.
그럼 많은 도움이 되었으면 하면서 필자에게 더 자세한것을 묻고 싶다면 댓글이나 필자에게
메일(dodari5882@hanmail.net)로 문의 하라 ㅋ
부디 80만이 넘는 미취업자가 좋은데 취업하기를 바라면서 화이팅~
개인적인 여유의 시간이 없었던걸까.....?
정신없이 지났던 2달간 되돌아 봤을때 게을렀고 적응기간(?)을 마쳤다고 할 수 있겠다...
그동안 필자의 일들을 돌아보면
1. 무사히 마이팟 개편 및 오픈(4월 말 ~ 5월 중순) - http://tvpot.daum.net/my/Top.do?ownerid=DuLv7f.e9ag0
2. 다음 tv팟 스타동 서비스 알바 ㅋ (5월말) - http://tvpot.daum.net/star/Top.do
3. 업무외 Java Study (아직 못끝냈다 ㅜㅜ) (5월초 ~ 진행중)
4. tv팟 ??팟 서비스 오픈 준비 (6월초 ~ 진행중) - 곧 오픈합니다. 많은 관심 부탁합니다.
5. 다음 정직원 발령 (7월 1일) - 정말 좋아 ㅋㅋ
약 두달여동안 많은 일이 있었다. 뭐 별루라고 생각할지 모르겠지만 정말 힘들었다 ㅋㅋㅋㅋ
최근 필자가 관심가지는 부분은
1. 주식, CMA, 펀드, 재태크 - 젊고 미혼일때 해보자 ㅋㅋ
2. tv팟 서비스 및 기술의 미래
3. 사회.... 촛불집회, 경제, 고유가 등등 기본은 알고 살아야 할거 같드라 ㅋㅋㅋ
블로그에 많은걸 다루지는 못하겠지만 많은 사람과의 정보 공유와 개인적인 표현은 블로그가 가장
나을거라는 생각을 했다 ㅋㅋㅋㅋ
기대하라 No7Do Season 2(?) ㅋ